 技術專欄
技術專欄
提到AI 人工智慧 、machine learning 機器學習 、deep learning 深度學習,第一想到的絕對是Nvidia 的GPU Server (DGX System),而在做AI分析儲存設備 Storage / NAS 是絕對不能忽視的角色,但在眾多的儲存設備裡,該選擇什麼樣的儲存設備才適合AI應用,Nvidia DGA A100 與Dell EMC PowerScale F800 all flash NAS ( 全閃存 ) 有針對deep learning 深度學習,有提供一份測試,可以給有此需求的人提供參考。
本文檔展示了 Dell EMC PowerScale / Isilon F800 全閃存橫向擴展 NAS 和配備 NVIDIA® A100 Tensor Core GPU 的 NVIDIA DGX™ A100 系統如何用於加速和擴展深度學習訓練工作負載
執行摘要
深度學習 (DL) 技術使模型能夠從現有數據中學習,然後做出相應的預測,從而在計算機視覺、自然語言處理 (NLP)、遊戲和自動駕駛等許多領域取得了巨大成功。成功歸功於改進算法的組合,
訪問更大的數據集和增加的計算能力。為了在企業規模上有效,DL 的計算強度需要高效的並行架構。系統組件的選擇和設計(針對 DL 用例精心選擇和調整)會對實施人工智能 (AI) 技術的速度、準確性和商業價值產生重大影響。
在如此苛刻的環境中,組織能夠依賴他們信任的供應商至關重要。
在過去幾年中,戴爾科技公司和 NVIDIA 建立了強大的合作夥伴關係,以幫助組織快速跟踪他們的 AI 計劃。我們的合作夥伴關係建立在為廣泛的產品組合提供靈活性和明智選擇的理念之上,這些產品組合結合了同類最佳的 GPU 加速計算、橫向擴展存儲和網絡。
本文重點介紹 Dell EMC Isilon F800 全閃存橫向擴展 NAS 如何通過提供性能、可擴展性和 I/O 並發性來滿足 NVIDIA DGX A100 系統對高性能 AI 工作負載的要求,從而加速 AI 創新。
適合對象
本文檔適用於有興趣使用高級計算和橫向擴展數據管理解決方案來簡化和加速 DL 解決方案的組織。 這些組織中的解決方案架構師、系統管理員和其他感興趣的讀者構成了目標受眾。
介紹
深度學習是人工智能的一個領域,它使用人工神經網絡使計算機能夠對複雜的現實世界模式進行準確的模式識別。這些新的創新水平幾乎適用於所有垂直行業。一些早期採用者包括先進研究、精準醫學、高科技製造、先進駕駛輔助系統 (ADAS) 和自動駕駛。
在這些初步成功的基礎上,人工智能計劃正在各個業務部門如雨後春筍般湧現,例如製造、客戶支持、生命科學、營銷和銷售。 Gartner 預測,僅到 2021 年,人工智能增強就將產生 2.9 萬億美元的商業價值。組織面臨著大量與數據相關的複雜選擇,
分析技能集、軟件堆棧、分析工具包和基礎設施組件;每一項都對上市時間和與這些舉措相關的價值產生重大影響。
在如此復雜的環境中,組織能夠依賴他們信任的供應商至關重要。在過去幾年中,戴爾科技集團和 NVIDIA 建立了強大的合作夥伴關係,以幫助組織加速其 AI 計劃。
我們的合作夥伴關係建立在為廣泛的產品組合提供靈活性和知情選擇的理念之上。我們的技術共同為成功的 AI 解決方案奠定了基礎,這些解決方案推動了高級 DL 軟件框架的開發,以 NVIDIA GPU 的形式提供大規模並行計算,用於並行模型訓練和橫向擴展文件系統,以支持並發性、性能和容量要求非結構化圖像和視頻數據集。
本文檔重點介紹 Dell Technologies 和 NVIDIA 合作的最新步驟,這是一種具有 Dell EMC Isilon F800 存儲和 DGX A100 系統的全新 AI 參考架構,可用於 DL 工作負載。這一新產品為客戶在部署可擴展的高性能 DL 基礎設施方面提供了更大的靈活性。包括使用 MLPerf 0.7 和微基準實用程序的標準圖像分類訓練基準的結果。
如圖 1 所示,DL 通常由兩個不同的工作流程組成,模型開發和推理。
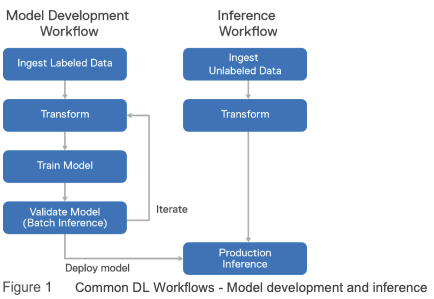
注意:Isilon 存儲和 DGX A100 系統架構針對模型開發工作流程進行了優化,該工作流程包括模型訓練和批量推理驗證步驟。 它既不用於生產推理,也沒有針對生產推理進行基準測試。
下面定義並詳細說明了工作流程步驟。
1. 攝取標記數據——標記數據(例如圖像及其標籤,表明圖像是否包含狗、貓或馬)被攝取到深度學習系統中。
2. 轉換——轉換包括在標記數據傳遞給 DL 算法之前應用於標記數據的所有操作。它有時被稱為預處理。對於圖像,這通常包括文件解析、JPEG 解碼、裁剪、調整大小、旋轉和顏色調整。
可以提前對整個數據集執行轉換,將轉換後的數據存儲在磁盤上。許多轉換也可以應用於訓練管道,避免存儲中間數據的需要。
3. 訓練模型——使用隨機梯度下降優化方法從標記數據中學習模型參數(邊權重)。在圖像分類的情況下,有幾種預先構建的神經網絡結構已被證明工作良好。
4. 驗證模型——一旦模型訓練階段以令人滿意的準確度完成,您將需要在驗證數據上測量它的準確度——模型訓練過程沒有看到的數據。
這是通過使用經過訓練的模型從驗證數據中進行推斷並將結果與正確的標籤進行比較來完成的。這通常稱為推理,但請記住,這是與生產推理不同的步驟。
5. 生產推理——通常將經過訓練和驗證的模型部署到可以執行實時推理的系統中。它將接受單個圖像作為輸入並輸出預測的類別(狗、貓、馬)。在某些情況下,輸入被批處理以獲得更高的吞吐量但更高的延遲。
圖 2 說明了參考架構,顯示了構成解決方案的關鍵組件,因為它經過測試和基準測試。 請注意,在客戶部署中,DGX A100 系統和 F800 存儲節點的數量會有所不同,並且可以獨立擴展以滿足特定 DL 工作負載的要求。 有關詳細信息,請參閱解決方案大小調整指南。
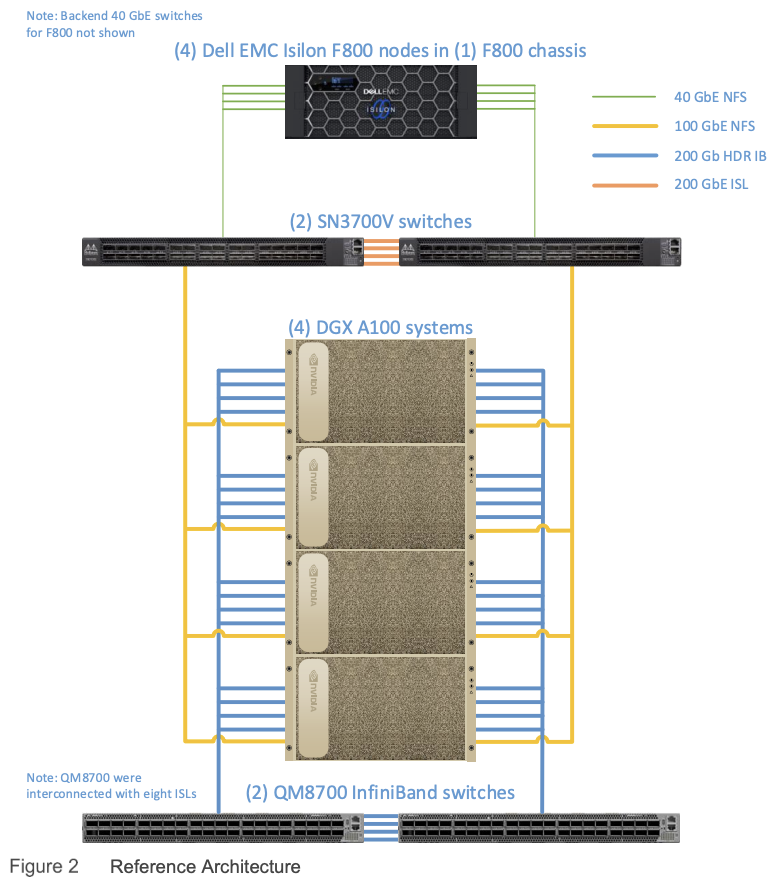
Dell EMC Isilon F800 代表第六代硬件,旨在運行經過充分驗證且可大規模擴展的 Dell EMC PowerScale OneFS 操作系統。 每個 Dell EMC Isilon F800 機箱(如圖 3 所示)包含四個存儲節點、60 個高性能固態驅動器 (SSD) 和八個 40 GbE 網絡連接。 OneFS 將 63 個機箱中的多達 252 個節點組合成一個高性能文件系統,旨在處理 I/O 密集程度最高的工作負載,例如 DL。 隨著性能和容量需求的增加,該平台可以簡單且無中斷地橫向擴展,從而允許應用程序和用戶繼續工作。

在本文檔中測試的解決方案中,在一個機箱中使用了四個 F800 節點。
Dell EMC Isilon F800 具有以下功能。
• 用於 AI 的低延遲、高吞吐量和大規模並行 I/O
- 每個機箱高達 250,000 個文件 IOPS,每個集群高達 1575 萬個 IOPS
- 每個機箱高達 15 GB/s 的吞吐量,每個集群高達 945 GB/s
- 每個機箱 96 TB 至 924 TB 原始閃存容量;每個集群高達 58 PB(全閃存)
這縮短了在 RAPIDS、TensorFlow、SparkML、Caffe 或專有 AI 平台等 AI 平台上訓練和測試數據集的分析模型的時間,從數十 TB 到數十 PB。
• 能夠使用多協議訪問在數據上就地運行 AI
- 多協議支持,例如 SMB、NFS、HTTP、S3 和原生 HDFS,以最大限度地提高操作靈活性
這消除了將數據和結果遷移/複製到單獨的 AI 堆棧的需要。通過向現有集群添加額外的 Isilon 節點,組織可以對 Isilon 上已有的相同數據執行 DL 和運行其他 IT 應用程序。
• 開箱即用的企業級功能
- 企業數據保護和彈性
- 強大的安全選項
這使組織能夠以最低的成本和風險管理 AI 數據生命週期,同時保護
數據並滿足監管要求。
• 極端規模
- 通過 Dell EMC PowerScale SmartPools 在全閃存、混合和存檔節點之間無縫分層
- 隨用隨增長的可擴展性,每個集群高達 58 PB 的閃存容量
- 只需連接電源、後端以太網和前端以太網,即可將新節點添加到集群中
- 隨著新節點的添加,存儲容量、吞吐量、IOPS、緩存和 CPU 增長
- 最多可連接 63 個機箱(252 個節點)以形成具有單個命名空間和單個一致緩存的單個集群
- 使用 Dell EMC PowerScale SmartDedupe 軟件可提高高達 85% 的存儲效率以降低成本
- 可選的數據去重和壓縮,可實現高達 3:1 的數據縮減
組織可以以經濟高效的方式大規模實現人工智能,使他們能夠處理具有高分辨率內容的多 PB 數據集,而無需重新架構和/或性能下降。
OneFS 有幾個關鍵特性,使其成為需要性能、並發性和規模的 DL 工作負載的出色存儲系統。下面列出了這些功能。
• 使用 Dell EMC PowerScale SmartPools 軟件的存儲分層使多個級別的性能、保護和存儲密度能夠在同一文件系統中共存,並解鎖在單個可擴展、無處不在的存儲資源中聚合和整合各種應用程序的能力水池。這有助於提供精細的性能優化、工作流隔離、更高的利用率和獨立的可擴展性——所有這些都通過單點管理。有關更多詳細信息,請參閱使用 Dell EMC Isilon SmartPools 進行存儲分層。
• OneFS 緩存基礎架構設計基於將集群中每個節點上的緩存聚合到一個全局可訪問的內存池中。這允許節點中的所有內存緩存可供集群中的每個節點使用。 OneFS 可以利用基於 Isilon SmartRead 組件使用的試探法的數據預取。
這極大地提高了所有協議的順序讀取性能,意味著在幾毫秒內讀取直接來自 RAM。
對於高順序情況,SmartRead 可以非常積極地提前預取,允許以非常高的數據速率讀取單個文件。有關更多詳細信息,請參閱 OneFS SmartFlash。
• OneFS 有一個完全分佈式的鎖管理器,可以協調存儲集群中所有節點上的數據鎖。高效的鎖定對於支持許多迭代 DL 工作負載所需的高效並行 I/O 配置文件至關重要,可實現高達數百萬的並發文件讀取訪問。有關更多詳細信息,請參閱 OneFS 技術概述。
本簡報中的基準測試是在 NVIDIA 的合作夥伴設施中進行的,所提到的網絡材料代表了他們在測試期間使用的設備。 Dell Technologies 提供專為構建高容量網絡結構而構建的架頂式交換機,以及專為構建幾乎任何規模的優化數據中心葉/主乾結構而設計的核心/聚合交換機。 Dell EMC PowerSwitch S 系列和 Z 系列在 Dell Technologies 的性能實驗室中經過測試和驗證,在行業測試(Tolly 和 IT Brand Pulse)中名列前茅,目前已部署在全球客戶數據中心。
NVIDIA Mellanox SN3700V 以太網交換機在 Isilon F800 集群節點和 NVIDIA DGX A100 系統之間提供高速“前端”以太網連接。 F800 節點通過 25GbE 或 40GbE 連接進行連接,DGX A100 系統通過 100GbE 或 200GbE 連接進行連接,SN3700 交換機以最小的延遲自動在不同速度的連接之間轉發流量。
SN3000 交換機基於 NVIDIA Spectrum-2 交換機 ASIC,專為現代數據中心打造,結合了高性能數據包處理、豐富的數據中心功能、云網絡規模和可見性。 靈活的統一緩衝區可確保在從 10Gb/s 到 200Gb/s 的任何端口和速度組合上獲得公平和可預測的性能,開放以太網設計支持多種網絡操作系統選擇,包括 NVIDIA Cumulus Linux、NVIDIA Onyx 和 SONiC。
NVIDIA Mellanox QM8700 InfiniBand 交換機在 DGX A100 系統之間提供高吞吐量、低延遲的網絡。 它們專為 EDR 100 Gb/s 和 HDR 200 Gb/s InfiniBand 鏈路而設計,它們最大限度地減少延遲並最大限度地提高系統之間所有 GPU 到 GPU 通信的吞吐量。 QM8700 交換機支持遠程直接內存訪問 (RDMA) 和網絡內計算卸載,用於人工智能和數據分析,以實現更快、更高效的數據傳輸。 它們支持 NVIDIA GPUDirect、用於基於網絡的 AI 和分析卸載(例如 MPI AllReduce)的 Mellanox SHARP,以及用於在自我修復網絡中實現最大彈性的 Mellanox SHIELD。
DGX A100 系統(圖 4)是一個完全集成的交鑰匙硬件和軟件系統,專為 DL 工作流程而構建。 每個 DGX A100 系統由八個 NVIDIA A100 Tensor Core GPU 提供支持,這些 GPU 使用 NVIDIA NVSwitch® 技術互連,為 GPU 間通信提供超高帶寬低延遲結構。
這種拓撲結構對於多 GPU 訓練至關重要,消除了與基於 PCIe 的互連相關的瓶頸,隨著 GPU 數量的增加,這些互連無法提供線性性能。 DGX A100 系統還配備了八個用於集群的單端口 NVIDIA Mellanox ConnectX-6 VPI HDR InfiniBand 適配器和兩個用於存儲和網絡的雙端口 ConnectX-6 VPI 以太網適配器,均支持 200Gb/s。

NVIDIA NGC™ 容器註冊表讓研究人員、數據科學家和開發人員可以輕鬆訪問全面的 GPU 加速軟件目錄,這些軟件可充分利用 NVIDIA DGX A100 系統,用於 AI、DL、機器學習 (ML) 和 HPC。 NGC 為當今最流行的 AI 框架提供容器,例如 RAPIDS、Caffe2、TensorFlow、PyTorch、MXNet 和 TensorRT,這些框架針對 NVIDIA GPU 進行了優化。這些容器集成了框架或應用程序、必要的驅動程序、庫和通信原語,並由 NVIDIA 在整個堆棧中進行了優化,以實現最大的 GPU 加速性能。 NGC 容器包含 NVIDIA CUDA® 工具包,該工具包提供 NVIDIA CUDA 基本線性代數子程序庫 (cuBLAS)、NVIDIA CUDA 深度神經網絡庫 (cuDNN) 等。 NGC 容器還包括用於多 GPU 和多節點集體通信原語的 NVIDIA 集體通信庫 (NCCL),為 DL 訓練啟用拓撲感知。 NCCL 支持單個 DGX A100 系統內的 GPU 之間以及多個 DGX A100 系統之間的通信。


軟體版本
為了衡量解決方案的性能,執行了來自 MLPerf Benchmark Suite 存儲庫的圖像分類基準測試。該基準測試使用 MXNet 在標記圖像上執行圖像分類卷積神經網絡 (CNN) 的訓練。本質上,系統學習圖像是否包含貓、狗、汽車、火車等。使用了著名的 ILSVRC2012 圖像數據集(通常稱為 ImageNet)。
該數據集包含 1,281,167 張訓練圖像,大小為 144.8 GB1。所有圖像都分為 1000 個類別或類。該數據集通常被 DL 研究人員用於基準測試和比較研究。
ImageNet 數據集中的單個 JPEG 圖像被轉換為 RecordIO 格式。數據集沒有調整大小,沒有標準化,也沒有對原始 ImageNet JPEG 圖像進行預處理。它保持 JPEG 格式提供的圖像壓縮,並且數據集的總大小保持大致相同(148 GB)。平均圖像大小為 115 KB。
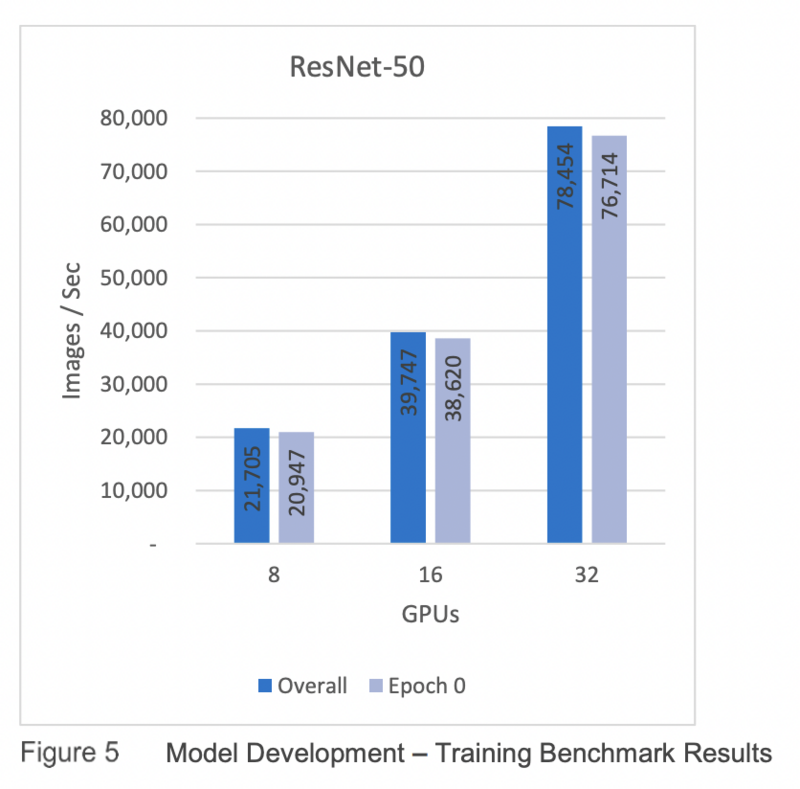
本節的基準測試結果是使用集群中的四個 F800 節點獲得的。每個結果是五次執行的平均值。
我們可以從圖 5 所示的基準中得出一些結論。
• 圖像吞吐量和存儲吞吐量從 8 個 GPU 線性擴展到 32 個。
• Epoch 0(從存儲中提取數據並緩存時)和Overall 之間的差異很小,因此存儲不是瓶頸。
1 本文檔中的所有單位前綴均使用 SI 標準(以 10 為基數),其中 1 GB 為 10 億字節。
深度學習訓練表現及分析
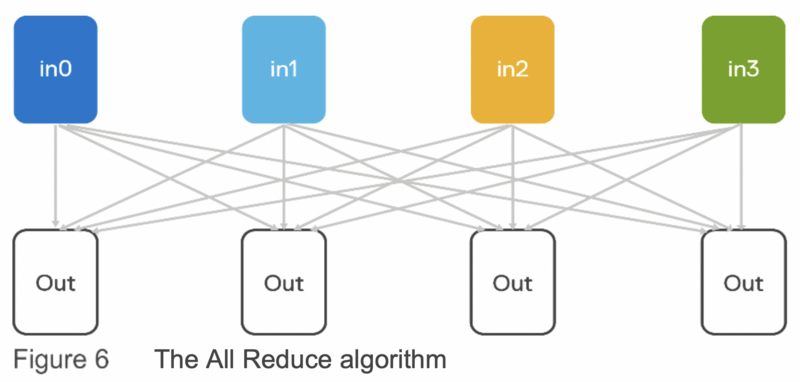
執行訓練時有兩種重要的網絡流量類型。 首先,讀取圖像(RecordIO 文件)需要 NFS 流量。 這使用以太網上的標準 TCP/IP。 其次,在每個 GPU 上計算的梯度(損失函數相對於每個參數的導數)必須與所有其他 GPU 的梯度求平均,並且所得的平均梯度必須分佈到所有 GPU。 這是使用 MPI All Reduce 算法以最佳方式執行的。 請參見下面的圖 6,它以最佳方式計算來自所有節點(頂部)的值的總和並將總和存儲在所有節點(底部)上。
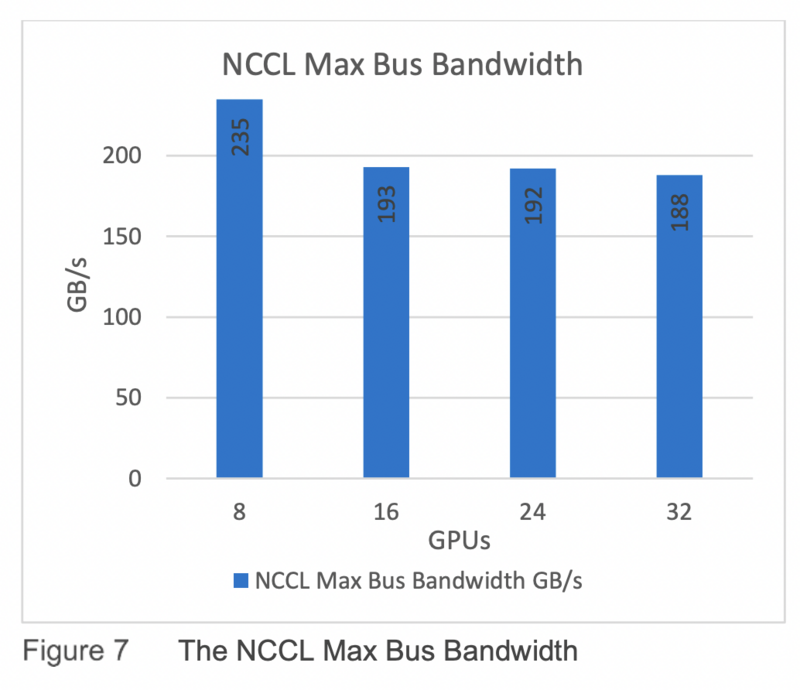
NCCL 在節點內和節點間的多個 GPU 上提供快速集合(例如 All Reduce)。 它支持多種互連技術,包括 PCIe、NVSwitch 技術、InfiniBand Verbs 和 IP 套接字。 NCCL 還自動調整其通信策略以匹配系統的底層 GPU 互連拓撲。 在 DGX A100 系統上正確配置後,NCCL 允許不同節點的 GPU 通過 PCIe 交換機、NIC 和 InfiniBand 交換機相互通信,繞過 CPU 和主系統內存。 圖 7 展示了 GPU 之間互連的性能。 我們可以看到,使用 8 個 GPU 時,帶寬高於 16 和 32。這是預期行為,因為使用 8 個 GPU,僅使用內部 NVLink 通信。
深度學習訓練表現及分析
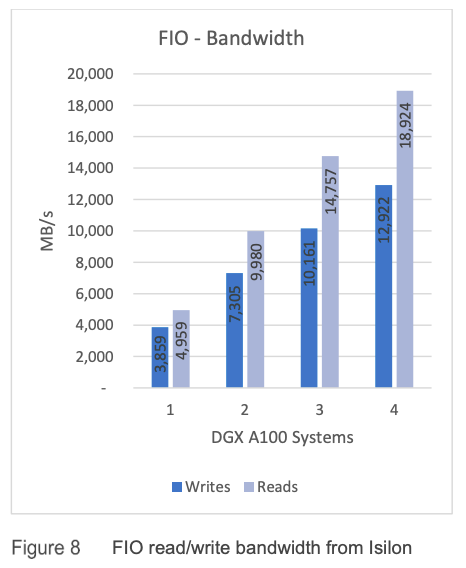
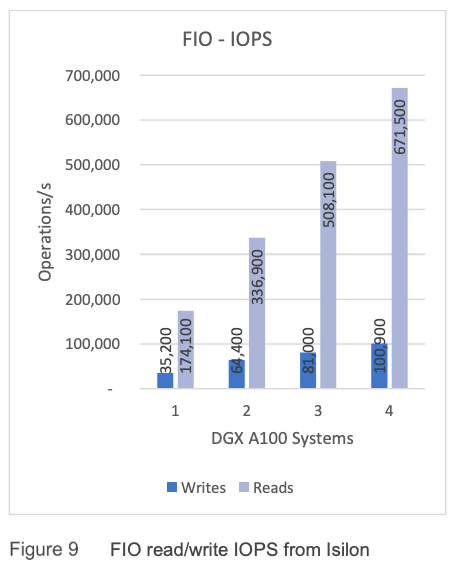
為了了解此環境中 Isilon 存儲 I/O 的限制,我們使用通用存儲基準測試工具 FIO 來執行讀取和寫入測試。 在這些測試中,每個 DGX A100 系統都指向不同的 F800 NIC,具有一對一的關係,這意味著對於四個 DGX A100 系統,只使用了一個帶有四個節點的 F800 機箱。 在實際生產工作負載中,強烈建議在 Dell EMC Isilon F800 集群內的每個可用節點之間分配負載以提高性能。 測得單個 DGX A100 系統以 4,959 MB/s 的速度從 Isilon 讀取數據,使該網絡接口的存儲鏈接 (40Gb/s) 飽和。 使用四個 DGX A100 系統,我們達到了四個 F800 節點的吞吐量限制,為 18,924 MB/秒,如圖 8 所示。我們還可以看到平台線性擴展,如圖 8 和圖 9 所示。
DL 工作負載在計算、內存、磁盤和 I/O 配置文件的需求方面差異很大,通常相差幾個數量級。 只有在預先知道這些資源要求時,才能提供有關 Isilon 節點的 GPU 數量和配置的大小指導。 也就是說,對於常見的圖像分類基準,在每個 Isilon 節點的 GPU 比率上有一些數據點通常是有益的。 根據 MLPerf 基準測試的結果,我們可以估計單個 F800 節點可以處理 8 個 NVIDIA A100 Tensor Core GPU。 總之,由四個節點組成的單個 Dell EMC Isilon F800 機箱可以為四個 NVIDIA DGX A100 系統提供此類圖像分類工作負載。
本文檔通過將 NVIDIA DGX A100 系統與 NVIDIA A100 Tensor Core GPU、NVIDIA Mellanox SN3700V 和 QM8700 交換機以及 Dell EMC Isilon F800 全閃存 NAS 存儲相結合,展示了面向 DL 的高性能架構。我們討論了 Isilon 的主要功能,這些功能使其成為 DL 解決方案的強大持久存儲。這種新的參考架構擴展了戴爾科技集團和 NVIDIA 必須通過我們無與倫比的聯合產品集使每個組織都可以輕鬆使用 AI 的承諾。我們一起為客戶提供明智的選擇和靈活性,幫助他們大規模部署高性能 DL。在整個基準測試中,我們驗證了 Isilon 全閃存 F800 存儲能夠與 DGX A100 系統保持同步并線性擴展性能。
需要指出的是,DL 算法對各種計算、內存、I/O 和磁盤容量配置文件有不同的要求。也就是說,本白皮書中提供的架構和性能數據點可以用作構建針對不同資源需求集量身定制的 DL 解決方案的起點。更重要的是,這個架構的所有組件都是線性可擴展的,可以獨立擴展,提供可以管理數十PB數據的DL解決方案。
雖然此處介紹的解決方案提供了多個性能數據點並說明了 Isilon 在處理大規模 DL 工作負載方面的有效性,但在 Isilon 上為 DL 保留數據還有其他幾個操作優勢:
• 能夠使用多協議訪問在數據上就地運行 AI
• 開箱即用的企業級功能
• 無縫分層到更具成本效益的節點
• 每個集群最多可擴展到 58 PB
總之,基於 Isilon 的 DL 解決方案提供了容量、性能和高並發性,以消除 AI 的 I/O 存儲瓶頸。這為具有面向未來的橫向擴展架構的大型企業級 DL 解決方案提供了堅如磐石的基礎,可滿足您當前的 AI 需求並為未來擴展。