 技術專欄
技術專欄

在數位經濟時代,數據不再是企業的附屬品,而是重塑商業模式、提升決策效率的戰略性資產。然而,傳統數據架構的「數據孤島」與低效治理,正成為企業邁向 AI 驅動創新的最大瓶頸。如何建立一個能同時滿足資料工程、數據科學、商業分析與機器學習需求的統一數據平台,已是企業 IT 決策者必須優先思考的戰略問題。
作為全台首家 Databricks Select Tier 合作夥伴,IT 智能化最佳夥伴-MetaAge 邁達特將透過本文本,帶您深入了解 Databricks Lakehouse 平台如何透過整合式架構,突破傳統限制,融合數據湖的彈性+數據倉儲的效能,為企業提供一站式的數據與 AI 解決方案。
Databricks 是一個由 Apache Spark 團隊創辦的資料分析平台,作為領先業界的資料分析平台,Databricks 無縫整合了資料工程、資料科學、商業分析、機器學習等關鍵工作流程,徹底顛覆傳統數據處理的繁瑣與低效,協助企業快速處理與分析大量的資料。
此外,Databricks 的最大優勢在於其雲端原生架構。Databricks 原生支援多種雲端平台(如 AWS、Azure、Google Cloud),讓使用者無需擔心底層基礎設施,可將寶貴的資源和時間,專注於更有價值的資料分析應用上與創新,加速實現數據驅動的商業目標。
在深入了解 Databricks 的強大功能之前,不妨先掌握幾個基本概念,將有助於您更好地理解其運作方式:
Workspace 是存取所有的 Databricks 資源的主要環境,透過直觀的資料夾方式,統一分類並管理各種數據物件,包含 Notebooks、Libraries、Dashboards、 和 Experiments 等。它更提供精細化的權限控管機制,方便使用者控管資料物件和運算資源的存取權限、存取安全和合規性,可謂團隊協作的數據指揮中心。
Notebook 是一個互動式的網頁應用介面,讓使用者能夠在同一頁面中,流暢地撰寫可執行的程式碼(支援多種語言,如 Python、Scala、SQL、R)、生成視覺化圖表與說明文字。這大大提升了資料處理、分析流程與機器學習模型的開發效率和可讀性。
Repos 提供與 Git 儲存庫的深度整合能力,讓開發者能將 Notebook 和原始碼輕鬆同步至 GitHub、GitLab 或 Bitbucket 等 Git 平台,實現專案版本控制,並提供專案的來源,有助團隊管理原始碼版本、追蹤修改歷程,確保專案的可追溯與一致性。
圖 1:Databricks 的 Workspace (工作區)、Notebook(筆記本)、Repos(代碼庫)
長期以來,隨著企業資料量快速增長,企業正面臨「數據孤島」與「複雜治理」的雙重挑戰:
資料孤島:企業資料時常散落在多個來源中,企業將各種格式(包括結構化、半結構化、非結構化)的原始資料存在資料湖,需進行大量分析的結構化資料則放在資料倉儲,使企業需維護獨立的資料系統,不僅大幅增加管理成本,也造成資料格式不一致等問題,導致資料價值無法有效發揮。
複雜的資料治理:在分散的數據環境中,難以追溯資料來源及集中管理資料訪問權限,進一步提高了資料治理的複雜性。
而 Databricks 所推出的革命性 Lakehouse(湖倉一體) 架構,正是為了解決這些痛點而生。Databricks 整合了 Data Lake 的「彈性與規模」與 Data Warehouse 的「查詢效能及資料治理能力」。這款創新的架構,讓企業可以在同一個平台上完成所有資料相關作業,避免使用孤立系統來處理不同的工作負載,大幅簡化系統架構,使資料團隊能迅速運用數據,而無需跨多個系統查詢。
此外,Databricks Lakehouse 還整合了以下您不可不知的關鍵技術:
Delta Lake(數據一致性與時間追溯的基石):支援 ACID 交易的儲存層,確保資料寫入的一致性與可靠性,並提供時間旅行 Time Travel、版本控制與即時查詢能力。
Unity Catalog(跨平台統一數據治理):統一的資料目錄與存取控管系統,支援跨工作區與雲環境的治理,提升資料安全性與合規性。
單一工作平台(提升團隊協作效率):將資料工程、資料科學、BI 分析與機器學習整合於同一工作空間,提升團隊協作效率,避免工具切換造成的摩擦。
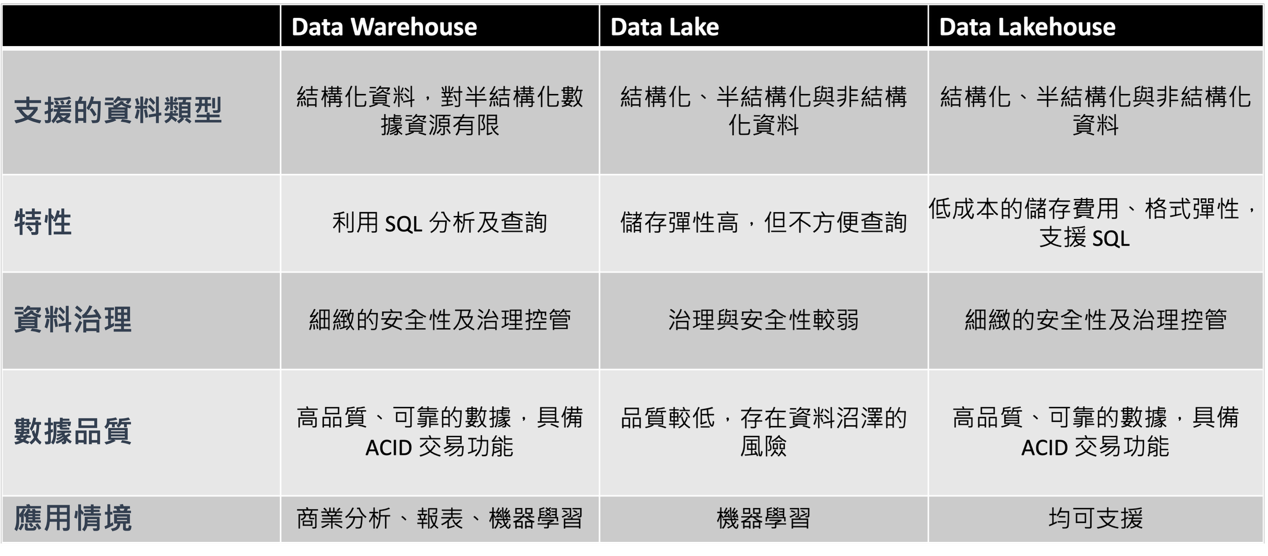
表 1:Lakehouse(湖倉一體)架構整合了 Data Warehouse 的結構化管理優勢,以及 Data Lake 的靈活性,提供統一的資料平台解決方案
Databricks Lakehouse 平台的強大功能,使其成為多種關鍵商業應用場景的首選,已為無數企業驅動創新並加速決策:
加速商業分析:無縫整合來自 ERP、CRM、CSV 上傳、第三方系統等多元資料源。在 Lakehouse 上做統一查詢與生成報表後,可再整合 Power BI、Tableau 或 Databricks SQL 進行即時儀表板展示,實現數據驅動的敏捷決策。
高效 IoT 資料處理:輕鬆蒐集來自 IoT 的即時串流設備資料,並與結構化資料結合,進行生產效率分析、預測性維護等應用,提升整體營運效率。
機器學習與 AI 模型開發:從資料前處理 → 特徵工程 → 模型訓練 → 模型部署與版本控管,整個機器學習生命週期都能在 Databricks 平台上順暢完成。且平台原生支援 MLflow 管理,簡化模型管理與追蹤的複雜性,加速 AI 應用落地。
為讓讀者更了解 Databricks Lakehouse,邁達特實際演示 Databricks Lakehouse 架構在處理異質資料(CSV 與 JSON)時的整合與分析流程。本次選用兩個政府資料開放平台中的實際資料進行示範,並將資料存放在 Amazon S3,分別為:
資料來源:政府資料開放平台
內容說明:記錄台北捷運每日的總運量
格式:結構化的 CSV 檔案,適合直接匯入並轉為 Delta Table 處理。
資料來源: Accuweather
內容說明:提供每日觀測的氣象資訊,包含每日最高溫度以及最低溫度。
格式:半結構化的 JSON 檔案,透過 Databricks 能夠輕鬆解析並轉換為可查詢格式。
操作步驟如下:
先將異質的資料上傳至 Amazon S3,並將 Databricks 與 S3 進行串接
從兩種資料來源中提取資料,轉成 Delta 格式。Delta 格式的優勢在於具有 ACID 交易功能、資料版本追蹤等。建立 Delta 後,可以使用 spark.read.table 快速讀取這些資料,進一步將兩者資料合併成完整的報告。
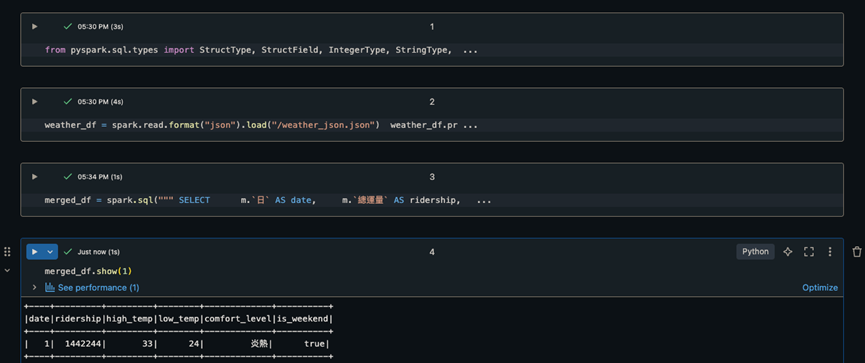
上述步驟充分展現了 Databricks 在處理異質資料、簡化資料流程及支援資料分析的強大能力。
Databricks 所提出的 Lakehouse 架構,成功融合了 Data Lake 的彈性與 Data Warehouse 的效能與治理能力,為資料處理與分析提供了一個高整合度、高擴充性的解決方案。不論是在商業分析、IoT 串流處理,還是機器學習開發等領域,Databricks 都能提供完整且一致的操作環境。
未來,隨著資料規模與型態日益複雜,Databricks 的 Lakehouse 架構將成為企業統整資料、加速決策的關鍵平台。透過本文的實際操作範例,相信您可以更清楚理解 Databricks 在資料整合、格式轉換與查詢效率方面的優勢。
在台灣,選擇一個具備原廠級實力與在地服務經驗的夥伴,將是成功部署 Databricks Lakehouse 平台的關鍵。IT 智能化最佳夥伴 — MetaAge 邁達特是 Databricks 在台首家 Select Tier 授權合作夥伴,具備 15 張以上 Databricks Professional Level Certified 認證,可為您提供 Databricks 諮詢、導入、優化、維運等完整服務,也可提供完整的機器學習生命週期管理服務,加速模型從開發到部署的時程。
此外,所有服務都可配備中文教育訓練、技術諮詢與全天候維運支援,確保您的企業能充分發揮 Databricks 平台的效益,成為您實現數據戰略目標的最強助攻!
全台首家授權,原廠級服務品質:
邁達特是 Databricks 在台灣首家授權夥伴,擁有最全面、最即時的技術支援、產品更新與培訓資源,能為客戶提供原廠級服務品質。
近三十年經驗,深度在地專業:
邁達特深耕台灣市場近三十年,擁有豐富的產業經驗與對本地企業需求的深刻理解,能提供最貼近您業務痛點的客製化解決方案。
強大技術團隊:
邁達特擁有業界領先的 Databricks 專業認證工程師團隊,從戰略規劃、系統架構設計、實施部署、資料遷移到平台優化與全天候維運,提供端到端的服務支援。
多雲整合領導者:
邁達特兼備 AWS、Azure、Google Cloud 三大公有雲代理資格,能確保 Databricks 在任何複雜雲端環境下的無縫部署與高效運作,助您實現真正的多雲數據戰略。
憑藉深厚技術實力與在地服務優勢,邁達特將成為您的企業在 AI 數據時代最堅實的戰略盟友。您有任何 Databricks 或 AI 資料平台的需求嗎?歡迎由此【免費咨詢邁達特】,讓邁達特專家團隊為您的企業分析數據現況,量身打造 Databricks 導入策略,全面駕馭數據力量,加速智慧轉型。
【立即與台灣首獲 Databricks 授權夥伴邁達特聯繫】
A1:Databricks 是由 Apache Spark 團隊創辦的統一數據與 AI 平台。Databricks 成功將資料工程、資料科學、商業分析與機器學習等工作流程,整合在單一閉環環境中,主要解決了企業長期面臨的「數據孤島」和「複雜治理」兩大痛點,大幅簡化數據基礎設施與管理複雜度。
A2:Lakehouse 架構正是 Databricks 的核心創新。它成功融合了傳統數據湖(Data Lake)的彈性與規模,以及數據倉儲(Data Warehouse)的高效查詢效能和嚴謹的資料治理能力。其優勢在於提供統一平台處理所有數據作業、簡化系統架構、加速數據洞察獲取、確保數據可靠性(透過 Delta Lake 的 ACID 交易)、以及實現跨雲數據治理(透過 Unity Catalog)。
Q3:建議您聯繫擁有豐富 Databricks 實作經驗與數據專業知識的 Databricks 合作夥伴進行導入評估。在台灣,您可聯繫 Databricks 台灣首家 Select Tier 授權合作夥伴 MetaAge 邁達特進行專業諮詢。邁達特的專家團隊將評估您目前的數據架構和業務需求,為您量身打造中文的 Databricks Lakehouse 導入策略,包括:系統架構設計、資料遷移規劃、平台實施部署、中文團隊培訓以及後續的維運支援。